编者按:纵观众多隐私计算企业中,深耕医疗者寥寥,而启明创投投资企业锘崴科技便是这样一家以医疗先行的企业,锘崴科技在成立仅2年多的时间里,迅速成为了隐私计算赛道的闪耀新星,并且成为了“隐私计算+医疗”企业的突出代表。
日前,算力智库采访了锘崴科技联合创始人、董事长王爽,他分享了隐私计算行业的变化、决定隐私计算企业走得长远的关键因素、锘崴科技的下一步发展计划等话题。启明创投微信公众号经授权转载,以飨读者。

锘崴科技联合创始人、董事长王爽
以下为采访文字实录。
01/
B端的改变:从被动学习到主动拥抱隐私计算
算力智库:理性客观评价,您觉得去年一年隐私计算整个行业有什么变化?
王爽:变化主要是隐私计算之前可能更多是偏技术和概念方向,但是随着2021《数据安全法》和《个人信息保护法》的实施,以及一些关于隐私安全的报道,曝光出来的与核心信息基础设施相关的安全风险,把隐私计算技术推到了一个风口上,很多机构、政府其实都开始主动询问怎么通过一些技术手段更好地保护数据,更合规地创造数据价值,之前可能还要靠隐私计算厂商去教育客户。
现在很多客户都倾向于主动来找厂商了解相关技术,或者是怎么能够把数据从收集、储存到共享、使用的过程变得更合规,这是一个比较重要的感受,就是从被动学习到主动拥抱隐私计算。
算力智库:这两年可以看到有越来越多的隐私计算公司开始冒头,据不完全统计,去年一年就新成立了70多家,您认为,隐私计算当下是“虚火”吗?
王爽:从两方面看,一方面也看出来是市场有需求,有需求才会有这么多供应,这是一个市场利好;另一方面这些企业中,可能绝大多数不具有底层技术架构,大部分是通过借用一些开源框架进行修改,去适应某些相关的场景,这存在潜在问题,就是会受限于开源框架的灵活性、安全性以及性能,很多客户发现使用这种开源框架进行部署后,可能性能达不到预想的要求,另外如果要添加一些新的功能,是难以扩充的。
我们定位是一家专业的隐私计算技术提供商,可以用不同的技术来根据用户场景做相应适配,提供基于用户场景,且兼容性能、安全性、精度等多要求下的最有效的一个解决方案。
算力智库:目前来看,隐私计算的商业模式以销售和服务为主,有产品销售或系统搭建模式,有运维服务模式,也有分润模式,您觉得,当下占隐私计算企业营收结构中主要的是哪一种?隐私计算的商业营收能力如何?未来在C端会有发挥空间吗?
王爽:现阶段的话,还是以系统搭建占主要比重,因为生态网络还在搭建的过程当中,只有这些数据节点,有了隐私计算的能力以后,它才会形成一个网。
这就有点像移动互联网还未兴起之前,刚开始肯定是搭建基站,要有足够多的基站,大家才都能用上5G或者4G手机,之后在上面才会有诸如美团这样相关的应用衍生出来,所以说目前阶段,隐私计算绝大多数是在搭建节点的过程当中,去构建网络。
但是在搭建的过程当中,其实大家都在去尝试,通过分润模式去实现一定程度的收入,我们也是通过跟一些机构,比如说政府的数据交易中心,以BOT的模式去做一些分润,或者跟一些商业化公司,通过CPA或者CPS,按点击和效果去获取一定收入。
系统搭建分成两种模式,一种是一次性搭建,附带一定时期的运维。比如说一个项目是3年,前3~6个月是进行搭建,后面2年主要是专注运维。这种模式目前看需求还是比较多的,比如医院、政府的数据交易中心,以及一些保险公司、金融机构渐渐都开始有搭建隐私计算系统的需求。
还有一种模式就是SaaS模式,按订阅收费,即通过提供一些标准的隐私计算接口,把客户的现有业务接入进来。比如说它在云上面需要跟用户进行数据交互,但是用户又担心在公有云或者是某些私有云平台上进行数据交互时,会泄露隐私,加上隐私计算的保护以后,可以保护企业在对用户提供服务的过程中,都是在可控、加密的状态下去实施的。
而在C端的话,更多体现在与场景结合。比如说我们和保险公司合作,这样其实是2B2C的模式,通过隐私计算触达到一些数据源,然后去做线索规划,帮他们实现更精准的获客,整个业务流程是在隐私计算平台上完成的。然后这种像CPA或者CPS分润模式其实也相当于是间接2C,这个市场里C端客户每完成一次交易,其实我们都可以实现分润。
算力智库:接上个问题,有一种说法,说隐私计算行业的发展逻辑有点像人工智能行业,技术壁垒比较高,投入大且“烧钱”,您怎么看?是不是很多企业还是靠融资在过活?
王爽:之所以说烧钱,是因为这个市场起来了,大家需要快速的扩张,所以才需要引入资本的力量,它的主要目的是帮助更好地去获得市场或者加大研发投入。
一如我刚才介绍的,隐私计算不光是简简单单像AI一样提供一个模型或者技术,它最终需要赋能于数据交易,这里面可能就涉及到一个数据网络的搭建,在搭建的过程中,其实有点类似于2C。比如说你要去做获客,要使2C的APP里有更多活跃用户,这里面的关键其实是要去获得活跃的数据源,过程中资本可以助力快速实现数据的生态网络。
02/
搭建数据网络,是必选项
算力智库:从您来看,能决定一家隐私计算企业活下来并且走得长远的关键因素是什么?
王爽:这个有几方面因素,肯定不是单一因素能决定的。第一方面我认为是技术方面,要有核心的隐私计算底层技术能支撑不同场景的应用,这个是能够走得比较长远的关键因素。
其次就是产品,光有技术,它没有实现产品化,还是没有办法服务于客户,所以底层的产品很重要。产品也分成几种,一种是基于某个细分领域的产品,专门服务于特定场景,比如说金融的征信、风控、获客;还有一种类型的产品,就是通用型产品,是一个底层隐私计算平台,在上面可以去开放一些生态,服务于不同领域。这两种产品我们目前看来都有相关的市场和生命力。
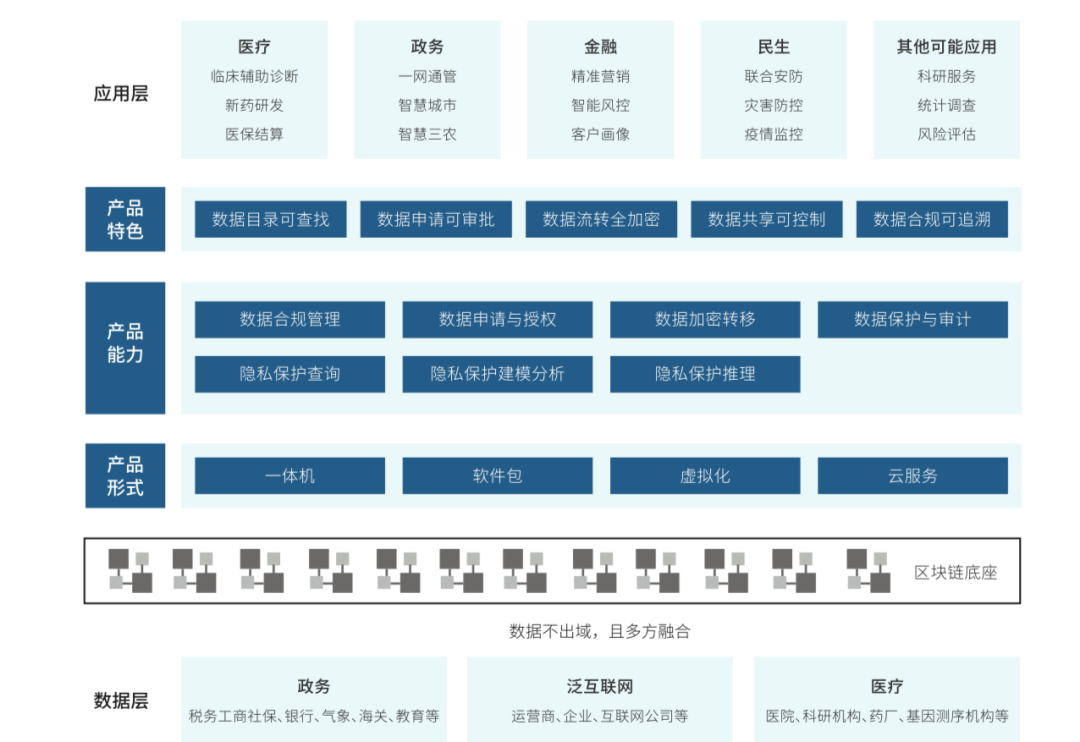
再者肯定是要有自己的数据网络,因为隐私计算技术,最终解决的还是数据提供方和数据使用方之间数据价值的转换。如果能够更好地促成数据使用方和数据提供方之间的应用的话,需要的是一个生态系统,这需要通过隐私计算技术支持,构建一些数据生态网络,从而服务于更多的应用场景,这也是非常重要的一点,可以形成网络效应。这个网络上有更多更好的数据,那就会有更好的应用去加入到网络里,也就会有更多的客户愿意为数据买单,反过来会激励更多的数据源继续加入到网络里,形成一个通过数据交易分润的长远模式。
算力智库:发现一个隐约的趋势,去年还能看到各厂商间在暗暗较劲,但今年,各家合作的新闻和消息似乎更频繁,从一力竞争到寻求竞合,您怎么看待这一现象?
王爽:有几方面,一方面是技术层面上的互补,因为每一家的技术都是有侧重点的,通过合作,可以实现更全面的一个技术栈。
另一方面是数据层面上的互补,每一家覆盖的数据源范围的广度、深度都是不一样的,通过多家合作,可以实现更广的数据源覆盖,去跟客户合作。
然后第三方面,就是互联互通的需求,因为同一个大的数据源,可能早期的时候布了很多家隐私计算系统,在这种情况下,如果再有新的合作产生,新加入的合作方布的系统可能不是在已部署系统的提供商范围内,这样就有两种解决方式,一种是需要重新去部署,另一种就是通过技术层面上的互联互通。后者目前来看是大家比较优先选择的方式。基于此,很多家的合作就能更好地促进隐私计算平台的互联互通,从而能够更快速、低成本地去接入新的应用场景。
算力智库:今年数据交易也进入了深化阶段,北数所、上海数据交易所先后成立,深圳数据交易所也在积极筹备,作为一家隐私计算企业,您觉得锘崴科技可以在其中扮演怎样的角色?
王爽:我们是北京数据交易所的成员,上海数据交易所我们也是首批加入,在上海称之为数商。数商可以从多种角度解读,可以作为数据提供商,也可以做数据运营技术提供商,也可以做数据使用方,这几方对于隐私计算公司来说,可能是会有多重角色的,因为很难有一个数据源,会提供足够多且足够广维度的数据,这些都是需要不同的数据源进行补充。
比如说我们在上海市数据交易中心里,我们既是技术提供商,也是部分数据提供商,通过隐私计算网络,帮他们去触达更多的数据,同时我们也能带来新的用户,比如我们的保险公司用户、银行用户,可能需要用到上海市数据交易中心的数据,基于这个层面,我们也起到了作为数据使用方的部分角色。
03/
趟医疗这条路,难却正确
算力智库:我们知道,隐私计算在金融领域的呼声更高,需求更盛,但锘崴科技却选择了先趟医疗这条路,率先建立了跨省级多中心全基因组关联分析,锘崴科技选择医疗先行的契机是什么?
王爽:一方面是源于我们的专业性,两位创始人——我和郑灏博士在医疗领域都工作了10多年,对于整个医疗行业,技术、应用以及市场都比较了解,这是从团队角度出发。
第二方面是医疗的市场其实非常大,在美国占了2020年GDP的18%,在中国也是非常大的一块(超过2020年GDP的7%),我们认为这个市场足够大,可以去撑起一家或者几家隐私计算公司。
然后第三方面,是整个医疗信息化建设在突飞猛进,很多医院都在转型智慧医院、智慧养老,对于数据共享、数据开放的需求非常大,未来会有更多的需求迸发出来。
再一个就是医疗对于技术的要求相对比较高,如果能够提供医疗场景解决方案的话,后期也可以去服务于其他非医疗领域,所以我们选择先从医疗领域入手。
算力智库:一如前述,隐私计算正处于大航海时代,几乎家家都说自己在做隐私计算,入局者有互联网大厂、数据安全方向的、区块链方向转型的,大数据厂商,人工智能公司等,坦白讲,您会有担忧吗?您觉得锘崴科技将何以突围而出?
王爽:我们认为有竞争是好事情,因为有竞争说明有需求,大家都看好这个市场,只要做好我们自己的优势就好了,因为锘崴科技的其中几项壁垒,还是跟其他的竞争对手有一定的差异性。
首先,我们是自研的隐私计算平台,已经开发了10多年,有比较深的底层技术,和一些专注于某个领域的隐私计算公司可能有一些差异化竞争,不是基于某个单一领域去做单一应用,而是提供一个通用的隐私计算平台。
再一个,就是我们在医疗领域有多年经验,将隐私计算跟医疗结合是我们另一个技术的壁垒,因为在医疗领域涉及到比较特殊的数据类型,比如说基因数据、医学影像数据,结构化或非结构化的病患数据,若在这些领域没有Domain Knowledge(领域知识)的话,很难短期内提供相关产品,并且医疗领域需要的分析方法论、参与方的个数,可能跟其他领域都不一样,一个医疗领域的应用可能需要十几家或者几十家医院的参与,所以在技术上是有一定的差异和壁垒的。
还有,就是在数据源方面,我们不光像竞争对手可以接入比如运营商、银联的数据,还有体检中心,医院的相关数据来做补充。在保险营销里,关心客户的信息不仅是用户的收入和财富信息,还包括用户的健康信息。这些体检机构、中心医院的数据源在竞争上给了我们一定的优势。

算力智库:据我们所知,您提出安全联邦学习早于Google,您为什么会关注到隐私计算领域?
王爽:我最早在美国读PhD的时候,就对数据安全比较感兴趣,之前在专注智能电表数据安全时,发现了很多数据安全的问题,然后提出了很多解决方案,通过分布式的计算,类似于联邦学习的前期应用,在每一家的电表上去做本地的计算,然后将小区用户或者城市层面的本地统计信息进行汇总、求和,传到电厂,帮助电厂去做发电的预算,这其实就是联邦学习的基本概念。
基于这些前期应用,后面我加入到UCSD,正好他们有类似的需求,每一家医院里都有自己的数据,但又受限于法律或者一些利益原因不能共享,然而很多的医学研究又需要大数据来支持,靠单个医院的数据体量是不够的。
在这种情况下,我们就想到了要将这种分布式的、数据可用不可见的联合数据查询建模分析的概念加以应用,就在这样的契机下,提出了相关的安全联邦学习技术,去帮助医院之间解决数据互联互通的问题。
算力智库:锘崴科技的下一步发展计划是什么?
王爽:下一步发展计划主要是以市场为驱动,前期肯定还是在数据节点搭建的过程当中,我们会继续投入很多的资源和精力来搭建数据生态网络,去丰富数据源,在数据源上创造更多的相关场景。
有更多的场景就需要在技术层面上去适配,因此在技术研发上,我们也一直在持续加大投入,利用隐私计算去赋能不同领域的应用,或者是在某个领域里做得更深,去支持更深度、高效、精准的应用。与此同时,我们会始终去尝试通过分润模式实现隐私计算价值转化的终极目标,建立数据交换平台,通过我们自己或者与第三方合作,比如省级的数据交易中心或其他平台来一起去实现。
来源 | 算力智库
